When I started programming as a lad, I initially used INI files to manage configuration settings. Lightweight and easy to parse, they were a simple way to get started, whether I was rolling my own parsing or, later, using existing parsing utilities. Soon, however, the allure of the Windows Registry drew me in, and I began using it almost exclusively for configuration settings. I found the registry convenient for most purposes, and only resorted to INI files for portable applications that I would run from a disk. This state of affairs lasted almost a decade, until I started to encounter registry permission problems on newer operating systems with improved user security controls. I finally started adopting some different configuration mechanisms.
The Application Settings mechanism is the default way to persist and manage application configuration settings in .NET. For those who prefer to adjust the behavior, it supports custom persistence implementations. This feature allows design-time development of application and user settings, and is improved by adding ConfigurationValidatorAttribute constraints.
And now, here I go, flying in the face of convention. I dislike managing settings outside the scope of the code that will use them, so I have written a PropertyManager which uses generics, reflection and delegates to provide a good alternative to the built-in Application Settings. It allows the declaration of properties at a more reasonable scope, automated discovery, and simple run-time management.
private static readonly IPropertyState<ByteSizesSmall> PROPERTY_SEGMENT_SIZE;private static readonly IPropertyState<bool> PROPERTY_REUSE_TILING;static ProcessingSet(){ PROPERTY_SEGMENT_SIZE = Context.RegisterOption(Context.OptionCategory.Tiling, "MaxSegmentSize", ByteSizesSmall.MB_256); PROPERTY_REUSE_TILING = Context.RegisterOption(Context.OptionCategory.Tiling, "UseCache", true);}
Once the properties have been defined, they can be used easily through the Value property, similar to the usage of a Nullable<T>.
if (PROPERTY_REUSE_TILING.Value){ // do something exciting}
So, what makes this all happen? Other than some validation, it boils down to the call to PropertyManager.Create().
public static IPropertyState<T> RegisterOption<T>(OptionCategory category, string name, T defaultValue){ if (!Enum.IsDefined(typeof(OptionCategory), category)) throw new ArgumentException("Invalid category."); if (string.IsNullOrWhiteSpace(name)) throw new ArgumentException("Option registration is empty.", "name"); if (name.IndexOfAny(new[] { '.', '\', ' ', ':' }) > 0) throw new ArgumentException("Option registration contains invalid characters.", "name"); string categoryName = Enum.GetName(typeof(OptionCategory), category); string optionName = String.Format("{0}.{1}", categoryName, name); IPropertyState<T> state = null; var propertyName = PropertyManager.CreatePropertyName(optionName); if (c_registeredProperties.ContainsKey(propertyName)) { state = c_registeredProperties[propertyName] as IPropertyState<T>; if (state == null) throw new Exception("Duplicate option registration with a different type for {0}."); WriteLine("Duplicate option registration: ", propertyName); } else { state = PropertyManager.Create(propertyName, defaultValue); c_registeredProperties.Add(propertyName, state); c_registeredPropertiesList.Add(state); } return state;}
The static property manager contains the necessary methods to create, update and retrieve properties. It wraps an IPropertyManager instance which knows the details about persistence and conversion for the storage mode that it represents. I have standard implementations for the Registry, XML, and a web service.
public interface IPropertyManager{ PropertyName CreatePropertyName(string name); PropertyName CreatePropertyName(string prefix, string name); IPropertyState<T> Create<T>(PropertyName name, T defaultValue); bool SetProperty(PropertyName name, ISerializeStateBinary value); bool GetProperty(PropertyName name, ISerializeStateBinary value); bool SetProperty(IPropertyState state); bool GetProperty(IPropertyState state);}
As for data binding, just create a DataGrid with a TwoWay binding on Value, and we have ourselves a property editor.
dataGrid.ItemsSource = Context.RegisteredProperties;
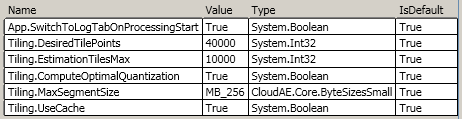
The main downside with this approach to application and user settings is that configuration validators cannot be used as attributes on the Value property of the IPropertyState<T>. The workaround for this is validation delegates which work just as well, but are not quite as nice visually.