I finally found some time to finish my SATR tiling algorithm for CloudAE. Unlike the previous STAR algorithms, which were built around segmented tiling, this approach uses more efficient spatial indexing to eliminate temporary files and to minimize both read and write operations. Another difference with this approach is that increasing the allowed memory usage for the tiling process will substantially improve the performance by lowering the duplicate read multiplier and taking advantage of more sequential reads. For instance, increasing the indexing segment size from 256 MB to 1 GB will generally reduce the tiling time by 50% on magnetic media, and 30% on an SSD.
Joshua Morey | 2013-03-14
SATR Development Finalized
Joshua Morey | 2012-10-29
MatSu Point MacKenzie in LAZ
The Matanuska-Susitna Borough's 2011 LiDAR & Imagery Project has been around for a while now, but I recently discovered that the Point MacKenzie data on the public mirror has been made available as compressed LAZ. The LASzip format is not ideal for all purposes, but it is always a major improvement when data servers provide data in LAZ format because of the massive reduction in bandwidth and download times.
Even when CloudAE did not support LAZ directly, it was always well worth it to download the compressed data and convert it to LAS. Now that CloudAE supports LAZ, everything is much simpler.
Joshua Morey | 2012-10-26
Point Enumeration in CloudAE
In my last post, I referenced the block-based nature of point cloud handling in CloudAE. The following example shows the basic format for enumerating over point clouds using the framework. At this level, the point source could be a text file, an LAS or LAZ file, or a composite of many individual files of the supported types. The enumeration hides all such details from the consumer.
using (var process = progressManager.StartProcess("ChunkProcess")){ foreach (var chunk in source.GetBlockEnumerator(process)) { byte* pb = chunk.PointDataPtr; while (pb < chunk.PointDataEndPtr) { SQuantizedPoint3D* p = (SQuantizedPoint3D*)pb; // evaluate point pb += chunk.PointSizeBytes; } }}
This can be simplified even more by factoring the chunk handling into IChunkProcess instances, which can encapsulate analysis, conversion, or filtering operations.
var chunkProcesses = new ChunkProcessSet( quantizationConverter, tileFilter, segmentBuffer); using (var process = progressManager.StartProcess("ChunkProcessSet")){ foreach (var chunk in source.GetBlockEnumerator(process)) chunkProcesses.Process(chunk);}
The chunk enumerators handle progress reporting and checking for cancellation messages. In addition, they hide any source implementation details, transparently reading from whatever IStreamReader is implemented for the underlying sequential sources.
Joshua Morey | 2012-10-25
Using LASzip from C#
Compiling LASzip is simple, but what what does performance look like when using LASzip in a managed environment? The first thing to realize is that accessing points individually is very expensive across a managed boundary. That means that using an equivalent of P/Invoke individually for each point will add a substantial amount of overhead in a C# context. To reduce the number of interop thunks which need to occur, the most important step is to write an intermediate class in native C++ which can retrieve the individual points and return them in blocks, transforming calls from this:
bool LASunzipper::read(unsigned char * const * point);
...to something like this:
int LAZBlockReader::Read(unsigned char* buffer, int offset, int count);
The next, less important, performance consideration is to create a C++/CLI interop layer to interface with the block reader/writer. This allows us to hide details like marshaling and pinning, and uses the C++ Interop, which provides optimal performance compared to P/Invoke.
For my situation, this is exactly what I want, since CloudAE is built around chunk processing anyway. For other situations, both the "block" transformation and the interop layer can be an annoying sort of overhead, so it should definitely be benchmarked to determine whether the thunk reduction cost is worth it.
The final factor determining the performance of LASzip is the file I/O. In LAStools, Martin Isenburg uses a default io_buffer_size parameter that is currently 64KB. Using a similarly appropriate buffer size is the easiest way to get reasonable performance. Choosing an ideal buffer size is a complex topic that has no single answer, but anything from 64KB to 1MB is generally acceptable. For those not familiar with the LASzip API, LASunzipper can use either a FILE handle or an iostream instance, and either of these types can use a custom buffer size.
One caveat that I mentioned in my last post is that when compiling a C++/CLI project in VS 2010, the behavior of customizing iostream buffer sizes is buggy. As a result, I ended up using a FILE handle and setvbuf(). The downside of this approach is that LAZ support in my application cannot currently use all my optimized I/O options, such as using FILE_FLAG_NO_BUFFERING when appropriate.
For an example of using the LASzip API from C++, check out the libLAS source.
Joshua Morey | 2012-09-19
LAZ Support
I have now added LASzip support to CloudAE. LASzip is a compression library that was developed by Martin Isenburg1 for compressing LAS points into an LAZ stream. Using the LASzip library, an LAZ file can be decompressed transparently as if it was an LAS source. This differs from the approach taken by LizardTech for the MG4 release of LiDAR Compressor, which does not necessarily maintain conformance to the LAS point types. Due to the compression efficiency and compatibility of the LAZ format, it has become popular for storing archive tiles in open data services such as OpenTopography and NLSF.
I link to the LASzip library in a similar fashion as libLAS, while providing a C++/CLI wrapper for operating on blocks of bytes. As a result, I am able to pretend that the LAZ file is actually an LAS file at the byte level rather than the point level. This allows me to support the format easily within my Source/Segment/Composite/Enumerator framework. I merely needed to add a simple LAZ Source and StreamReader, and the magic doth happen. There is minimal overhead with this approach, since the single extra memcpy for each point is not much compared to decompression time.
LAZ writer support is similarly straightforward, but I am sticking with LAS output for now, until I have more time to determine performance impacts.
Thanks to Martin for his suggestions regarding implementation performance. It turns out there is a bug in the ifstream/streambuf when compiling with CLR support. I had to extract the stream operations into a fully native class in order to achieve the desired performance.↩
Joshua Morey | 2012-06-26
The Cost of Double.TryParse
After extensive testing, I have optimized the text to binary conversion for ASCII XYZ files. These files are a simple delimited format with XYZ values along with any number of additional attributes. My original naive approach used StreamReader.ReadLine() and Double.TryParse(). I quickly discovered that when converting billions of points from XYZ to binary, the parse time was far slower than the output time, making it the key bottleneck for the process.
Although the TryParse methods are convenient for normal use, they are far too slow for my purposes, since the points are in a simple floating point representation. I implemented a reader to optimize the parse for that case, ignoring culture rules, scientific notation, and many other cases that are normally handled within the TryParse. In addition, the parse performance of atof()-style operations varies considerably between implementations. The best performance I could come up with was a simple variation of a common idea with the addition of a lookup table. The main cost of the parse is still the conditional branches.
In the end, I used custom parsing to identify lines directly in bytes without the overhead of memory allocation/copying and converting to unicode strings. From there, I parse out the digits using the method I described. I also made a variation that used only incremented pointers instead of array indices, but in the current .NET version, the performance was practically identical, so I reverted to the index version for ease of debugging.
The following test code provides reasonable performance for parsing three double-precision values per line.
bool ParseXYZ(byte* p, int start, int end, double* xyz){ for (int i = 0; i < 3; i++) { long digits = 0; // find start while (start < end && (p[start] < '0' || p[start] > '9')) ++start; // accumulate digits (before decimal separator) int currentstart = start; while (start < end && (p[start] >= '0' && p[start] <= '9')) { digits = 10 * digits + (p[start] - '0'); ++start; } // check for decimal separator if (start > currentstart && start < end && p[start] == '.') { int decimalPos = start; ++start; // accumulate digits (after decimal separator) while (start < end && (p[start] >= '0' && p[start] <= '9')) { digits = 10 * digits + (p[start] - '0'); ++start; } xyz[i] = digits * c_reciprocal[start - decimalPos - 1]; } else xyz[i] = digits; if (start == currentstart || digits < 0) return false; // no digits or too many (overflow) } return true;}
Joshua Morey | 2012-02-27
Simulating points in WPF 3D
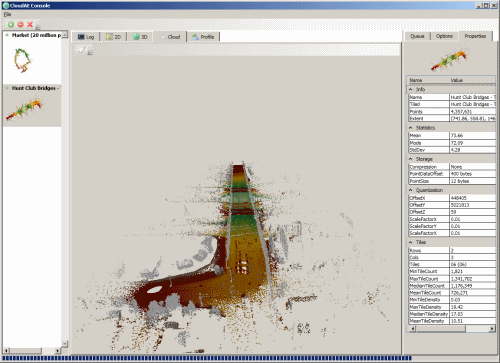 I have implemented a simple 3D point cloud visualization control intended to test whether WPF 3D can be reasonably used as a point cloud viewer. Up to this point, I have been rendering clouds using TIN geometry because WPF only supports meshes.
I have implemented a simple 3D point cloud visualization control intended to test whether WPF 3D can be reasonably used as a point cloud viewer. Up to this point, I have been rendering clouds using TIN geometry because WPF only supports meshes.
Using indexed meshes, I generated geometry that could represent points in 3D space. At first, I tried to make the points visible from all angles, but that required too much memory from the 3D viewer even for simple clouds. I reduced the memory footprint by only generating geometry for the top face of the pseudo-points, which allowed small clouds to be rendered. For large clouds, I had to thin down to fewer than 1m points before generating geometry. Even at this point, I was forced to make the point geometry larger than desired in order for it to not disappear when rendered.
The conclusion from this test is that WPF 3D is totally unsuitable for any type of large-scale 3D point rendering. Eventually, I will need to move to OpenGL, Direct3D, or some API such as OSG or XNA.
Joshua Morey | 2011-12-24
Edge Detection


Joshua Morey | 2011-12-23
Segmentation
 Since the framework performance has reached the goals that I set for myself, I have paused work on tiling optimizations and moved on to algorithm development. The first step was to build a raster format data source. I decided to go with a non-interleaved tiled binary format, which fits well with my intended usage. In the future, I will make a more robust determination of my needs with regard to raster support.
Since the framework performance has reached the goals that I set for myself, I have paused work on tiling optimizations and moved on to algorithm development. The first step was to build a raster format data source. I decided to go with a non-interleaved tiled binary format, which fits well with my intended usage. In the future, I will make a more robust determination of my needs with regard to raster support.
One of the first high-performance algorithms that I developed in years past was a basic region-grow. I have now implemented my tile-based segmentation algorithm (region-growing) for 2D analysis. This allows me to perform segmentation on an interpolated cloud or raster, using the tiles to allow a low memory footprint.
Soon, I will need to make a vector output source, possibly SHP. That will give me better geometry to visualize than the textured meshes I am currently using in the 3D viewer.
Joshua Morey | 2011-12-23
Tile Stitching
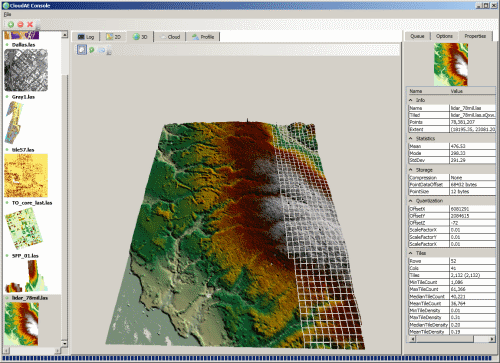 I have completed a basic tile stitching algorithm for use in completing the 3D mesh view. At this point, it only stitches equal resolutions, so it will stitch low-res tiles together and high-res tiles together, but it will leave a visible seam between tiles of different resolutions. Obviously, that is not a difficult problem, since I am only stitching regular meshes at this point. However, I do plan to get irregular mesh support eventually. Currently, I have an incremental Delaunay implementation, but the C# version is much slower than the original C++, to the extent that it is not worth running. The S-hull implementation that I downloaded is much faster, but does not produce correct results.
I have completed a basic tile stitching algorithm for use in completing the 3D mesh view. At this point, it only stitches equal resolutions, so it will stitch low-res tiles together and high-res tiles together, but it will leave a visible seam between tiles of different resolutions. Obviously, that is not a difficult problem, since I am only stitching regular meshes at this point. However, I do plan to get irregular mesh support eventually. Currently, I have an incremental Delaunay implementation, but the C# version is much slower than the original C++, to the extent that it is not worth running. The S-hull implementation that I downloaded is much faster, but does not produce correct results.
The primary limitation of the tile-based meshing and stitching is that WPF 3D has performance limitations regarding the number of MeshGeometry3D instances in the scene. For small to medium-sized files, there may be up to a few thousand tiles with the current tile-sizing algorithms. WPF 3D performance degrades substantially when the number of mesh instances gets to be approximately 12,000. Massive files may have far more tiles than that, and adding mesh instances for the stitching components makes the problem even worse. I have some ideas for workarounds, but I have not yet decided if they are worth implementing since there are already so many limitations with WPF 3D and this 3D preview was never intended to be a real viewer.

Joshua Morey | 2011-12-23
CloudAE Preview Announcement
CloudAE development has reached a preview stage, so I am beginning this blog to share my development efforts. I solve a number of problems as I develop applications, and I no longer have the energy to share solutions on forums and message boards. Perhaps I will find the motivation to provide details here as I run benchmarks and resolve issues that interest the community. We shall see.
